CMU Sphinx toolkit
Решил воспользоваться распознованием голоса с помощью cmusphinx, попробовал основную версию pocketsphinx, которая написана на большом кол-ве языков, в том числе python, но проблем возникло большое кол-во, поэтому решил воспользоваться Sphinx4, которая написана только на java.
На чем проводил тестирование:
- Windows: 10
- Java: jdk1.8.0_131
- gradle: 5.3.1
- IntelliJ IDEA 2019.1 Build: 191.6183.87
По шагам
1. git clone https://github.com/cmusphinx/sphinx4.git
2. открываем в IntelliJ склонированную директорию sphinx4
3. Меняем содержимое файла sphinx4-samples/build.gradle на следующее (добавил зеленые строчки):
description = 'Sphinx4 demo applications'
dependencies {
compile project(':sphinx4-core')
compile project(':sphinx4-data')
}
jar {
from configurations.compile.collect { it.isDirectory() ? it : zipTree(it) }
manifest {
attributes(
'Main-Class': 'demo.App'
)
}
}
4. Согласно руководству создаем файл sphinx4-samples\src\main\java\demo\App.java с немного измененным содержимым:
package demo;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import edu.cmu.sphinx.api.Configuration;
import edu.cmu.sphinx.api.SpeechResult;
import edu.cmu.sphinx.api.StreamSpeechRecognizer;
public class App {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setAcousticModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us");
configuration.setDictionaryPath("resource:/edu/cmu/sphinx/models/en-us/cmudict-en-us.dict");
configuration.setLanguageModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us.lm.bin");
StreamSpeechRecognizer recognizer = new StreamSpeechRecognizer(configuration);
InputStream stream = new FileInputStream(new File("sphinx4-samples/src/main/resources/edu/cmu/sphinx/demo/speakerid/test.wav"));
recognizer.startRecognition(stream);
SpeechResult result;
while ((result = recognizer.getResult()) != null) {
System.out.format("Hypothesis: %s\n", result.getHypothesis());
}
recognizer.stopRecognition();
}
}
5. Компилируем jar-файл:
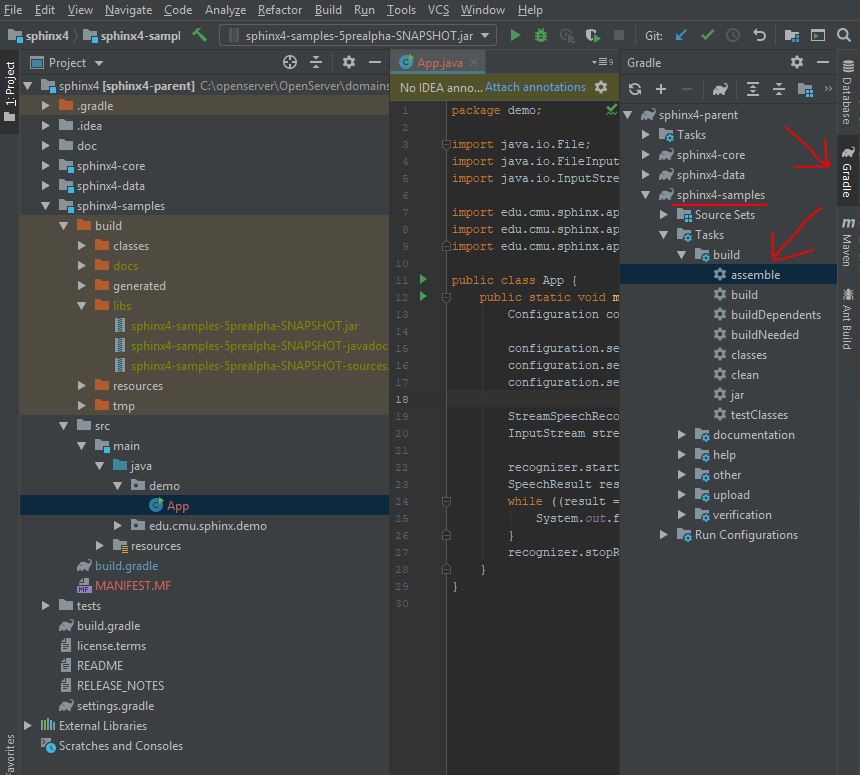
6. Запускаем jar:
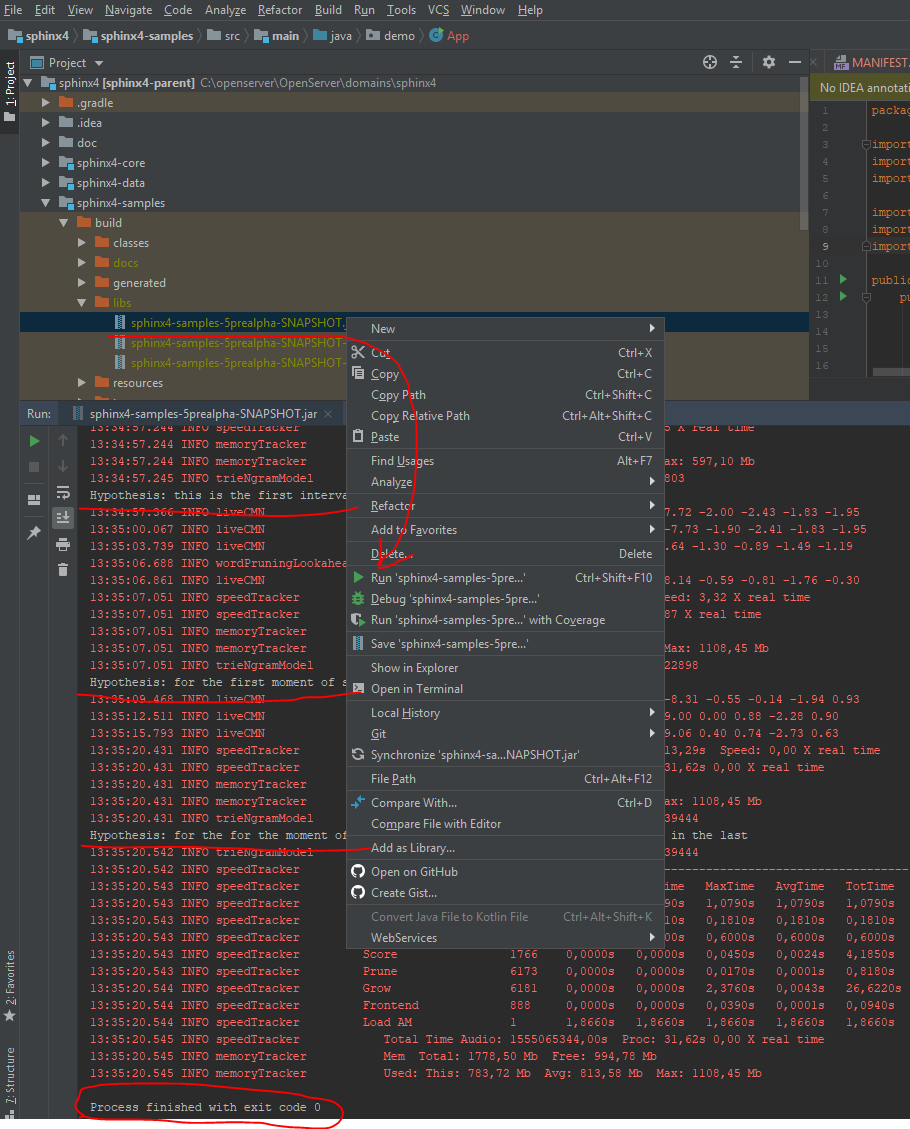
Все хорошо, обратите внимание на белые строчки начинающиеся с "Hypothesis: " это и есть распознанный текст файла "sphinx4-samples/src/main/resources/edu/cmu/sphinx/demo/speakerid/test.wav"
Следующий шаг LiveSpeechRecognizer (распознование с микрофона), тут следует заметить, что согласно документации в sphinx4 не поддерживается “Hot word listening”, т.е. данные будут распозноваться без прерывания, а значит разбор ключевых слов Вы должны делать самостоятельно.