Индексы в MySQL
Индексы в MySQL (Mysql indexes) — отличный инструмент для оптимизации SQL запросов. Чтобы понять, как они работают, посмотрим на работу с данными без них.
1. Чтение данных с диска
- Каждая таблица в MySQL является файлом, который в MySQL называется сегментом
- Каждый сегмент состоит из экстентов (понятие базы данных) размером 1 МБ (64 последовательных страниц по 16 КБ, или 128 страниц по 8 КБ, или 256 страниц по 4 КБ).
- Каждый экстент состоит из страниц (понятие базы данных).
- Каждая страница (см. ниже) состоит из блоков (понятие файловой системы).
- Каждый блок состоит из группы секторов, которые оптимизируют адресацию хранилища (понятие файловой системы), но не будем так сильно погружаться.
На жестком диске нет такого понятия, как файл. Есть понятие блок. Один файл обычно занимает несколько блоков. Каждый блок знает, какой блок идет после него. Файл делится на куски и каждый кусок сохраняется в пустой блок.
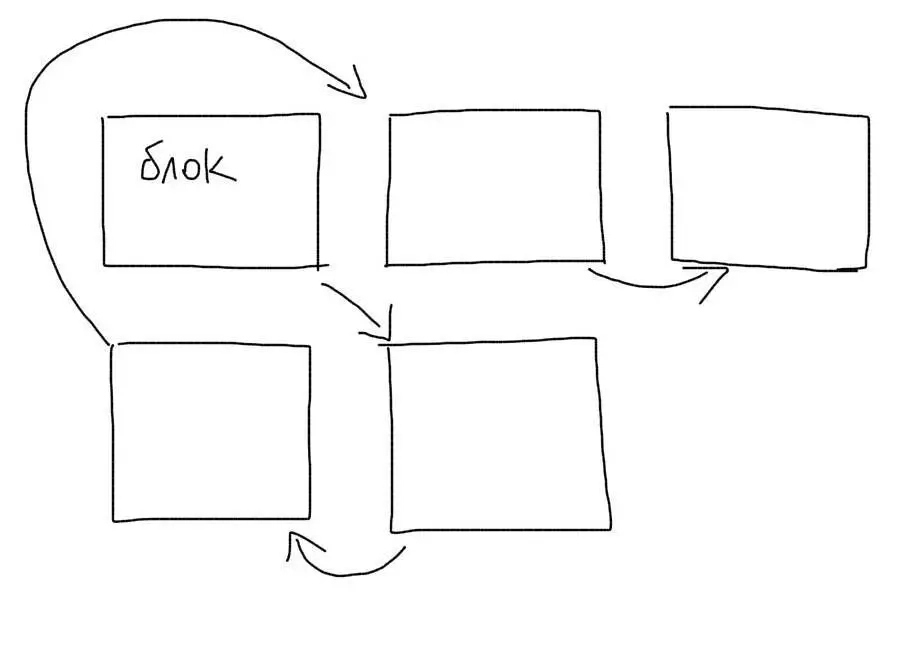
При чтении файла, приложение по очереди проходится по всем блокам и собираем файл из кусков. Блоки одного файла могут быть раскиданы по диску (фрагментация). Тогда чтение файла замедлится, т.к. понадобится прыгать к разным участкам диска.
Когда мы ищем что-то внутри файла, нам понадобится пройтись по всем блокам, в которых он сохранен. Если файл очень большой, то и количество блоков будет значительным. Необходимость перепрыгивать с блока на блок, которые могут находиться в разных местах, сильно замедлит поиск данных.
Подробнее
Страница (page) - единица измерения, представляющая, сколько данных InnoDB передает в любой момент времени между диском (файлами данных) и памятью (буферным пулом). Страница может содержать одну или несколько строк, в зависимости от объема данных в каждой строке. Если строка не помещается полностью в одну страницу, InnoDB устанавливает дополнительные структуры данных в стиле указателя, чтобы информация о строке могла храниться на одной странице.
Один из способов уместить больше данных на каждой странице - использовать сжатый формат строк. Для таблиц, использующих большие двоичные объекты или большие текстовые поля, компактный формат строк позволяет хранить эти большие столбцы отдельно от остальной части строки, уменьшая накладные расходы ввода-вывода и использование памяти для запросов, которые не ссылаются на эти столбцы.
Когда InnoDB читает или записывает наборы страниц батчами (чтобы увеличить пропускную способность ввода-вывода), он читает или записывает экстент за один раз.
Все дисковые структуры данных InnoDB в экземпляре MySQL имеют одинаковый размер страницы.
2. Поиск данных в MySQL
Выполним запрос такого вида:
SELECT * FROM users WHERE age = 29MySQL при этом открывает файл, где хранятся данные из таблицы users. А дальше — начинает перебирать весь файл, чтобы найти нужные записи.
Кроме этого, MySQL будет сравнивать данные в каждой строке таблицы со значением в запросе. Допустим работа ведется с таблицей, в которой есть 10 записей. Тогда MySQL прочитает все 10 записей, сравнит колонку age каждой из них со значением 29 и отберет только подходящие данные:
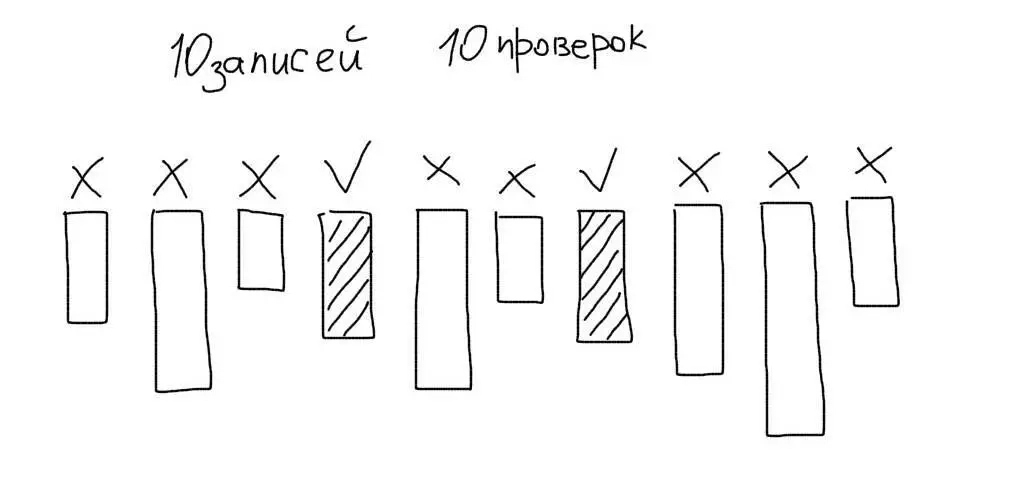
Итак, есть две проблемы при чтении данных:
- Низкая скорость чтения файлов из-за расположения блоков в разных частях диска (фрагментация).
- Большое количество операций сравнения для поиска нужных данных.
3. Сортировка данных
Представим, что мы отсортировали наши 10 записей по убыванию. Тогда используя алгоритм бинарного поиска, мы могли бы максимум за 4 операции отобрать нужные нам значения:
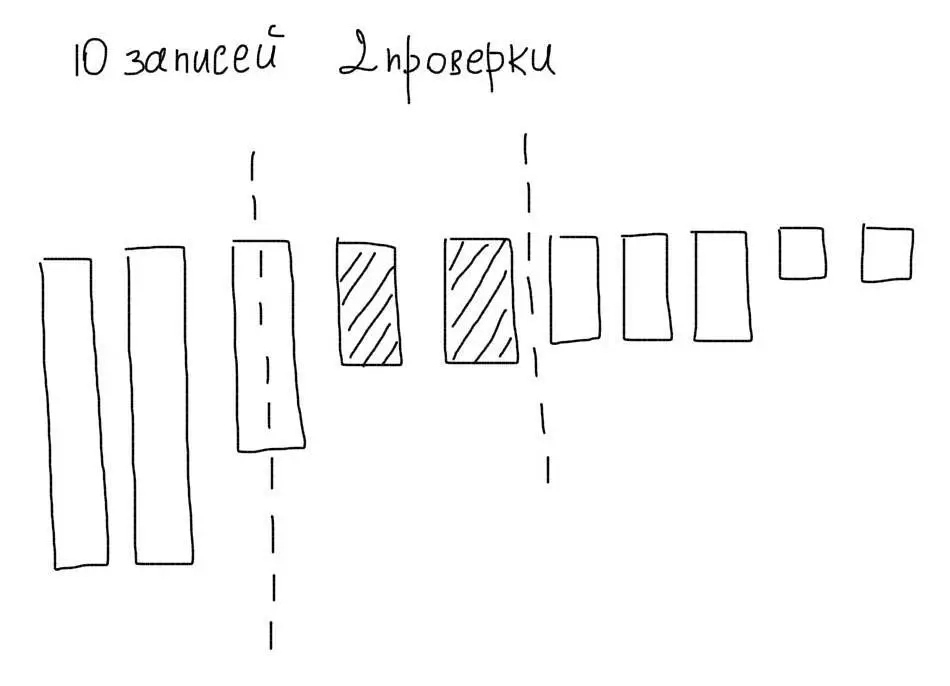
Кроме меньшего количества операций сравнения, мы сэкономили бы на чтении ненужных записей.
Индекс — это и есть отсортированный набор значений. В MySQL индексы всегда строятся для какой-то конкретной колонки. Например, мы могли бы построить индекс для колонки age из примера.
4. Выбор индексов в MySQL
В самом простом случае, индекс необходимо создавать для тех колонок, которые присутствуют в условии WHERE.
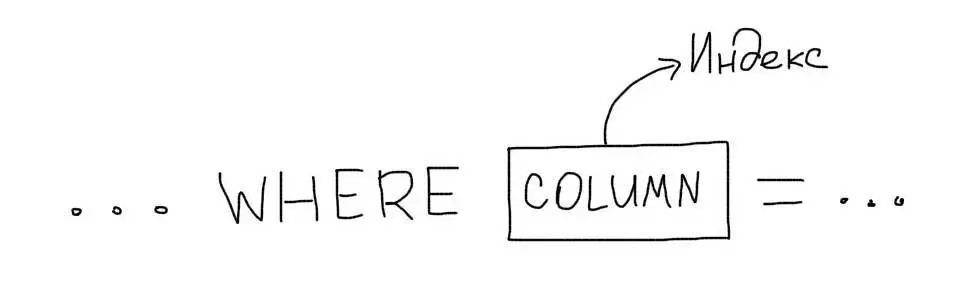
Рассмотрим запрос из примера:
SELECT * FROM users WHERE age = 29Нам необходимо создать индекс на колонку age:
CREATE INDEX age ON users(age);После этой операции MySQL начнет использовать индекс age для выполнения подобных запросов. Индекс будет использоваться и для выборок по диапазонам значений этой колонки:
SELECT * FROM users WHERE age < 29Сортировка
Для запросов такого вида:
SELECT * FROM users ORDER BY register_dateдействует такое же правило — создаем индекс на колонку, по которой происходит сортировка:
CREATE INDEX register_date ON users(register_date);Внутренности хранения индексов
Представим, что наша таблица выглядит так:
id | name | age
1 | Den | 29
2 | Alyona | 15
3 | Putin | 89
4 | Petro | 12После создания индекса на колонку age, MySQL сохранит все ее значения в отсортированном виде:
age index
12
15
29
89Кроме этого, будет сохранена связь между значением в индексе и записью, которой соответствует это значение. Обычно для этого используется первичный ключ:
age index и связь с записями
12: 4
15: 2
29: 1
89: 3Уникальные индексы
MySQL поддерживает уникальные индексы. Это удобно для колонок, значения в которых должны быть уникальными по всей таблице. Такие индексы улучшают эффективность выборки для уникальных значений. Например:
SELECT * FROM users WHERE email = 'golotyuk@gmail.com';На колонку email необходимо создать уникальный индекс:
CREATE UNIQUE INDEX email ON users(email)Тогда при поиске данных, MySQL остановится после обнаружения первого соответствия. В случае обычного индекса будет обязательно проведена еще одна проверка (следующего значения в индексе).
5. Составные индексы
MySQL может использовать только один индекс для запроса (кроме случаев, когда MySQL способен объединить результаты выборок по нескольким индексам). Поэтому, для запросов, в которых используется несколько колонок, необходимо использовать составные индексы.
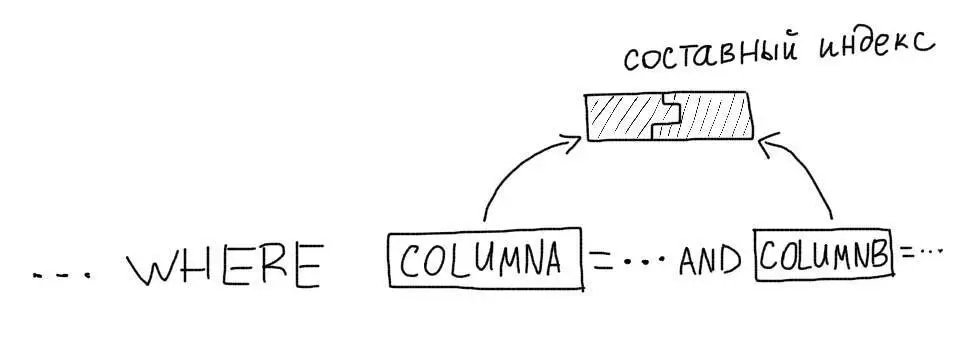
Рассмотрим такой запрос:
SELECT * FROM users WHERE age = 29 AND gender = 'male'Нам следует создать составной индекс на обе колонки:
CREATE INDEX age_gender ON users(age, gender);Устройство составного индекса
Чтобы правильно использовать составные индексы, необходимо понять структуру их хранения. Все работает точно так же, как и для обычного индекса. Но для значений используются значений всех входящих колонок сразу. Для таблицы с такими данными:
id | name | age| gender
1 | Den | 29 | male
2 | Alyona | 15 | female
3 | Putin | 89 | tsar
4 | Petro | 12 | maleзначения составного индекса будут такими:
age_gender
12male
15female
29male
89tsarЭто означает, что очередность колонок в индексе будет играть большую роль. Обычно колонки, которые используются в условиях WHERE, следует ставить в начало индекса. Колонки из ORDER BY — в конец.
Поиск по диапазону
Представим, что наш запрос будет использовать не сравнение, а поиск по диапазону:
SELECT * FROM users WHERE age <= 29 AND gender = 'male'Тогда MySQL не сможет использовать полный индекс, т.к. значения gender будут отличаться для разных значений колонки age. В этом случае база данных попытается использовать часть индекса (только age), чтобы выполнить этот запрос:
age_gender
12male
15female
29male
89tsar
Сначала будут отфильтрованы все данные, которые подходят под условие age <= 29. Затем, поиск по значению "male" будет произведен без использования индекса.
Сортировка
Составные индексы также можно использовать, если выполняется сортировка:
SELECT * FROM users WHERE gender = 'male' ORDER BY ageВ этом случае нам нужно будет создать индекс в другом порядке, т.к. сортировка (ORDER) происходит после фильтрации (WHERE):
CREATE INDEX gender_age ON users(gender, age);Такой порядок колонок в индексе позволит выполнить фильтрацию по первой части индекса, а затем отсортировать результат по второй.
Колонок в индексе может быть больше, если требуется:
SELECT * FROM users WHERE gender = 'male' AND country = 'UA' ORDER BY age, register_timeВ этом случае следует создать такой индекс:
CREATE INDEX gender_country_age_register ON users(gender, country, age, register_time);6. Использование EXPLAIN для анализа индексов
Инструкция EXPLAIN покажет данные об использовании индексов для конкретного запроса. Например:
mysql> EXPLAIN SELECT * FROM users WHERE email = 'golotyuk@gmail.com';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 336 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+Колонка key показывает используемый индекс. Колонка possible_keys показывает все индексы, которые могут быть использованы для этого запроса. Колонка rows показывает число записей, которые пришлось прочитать базе данных для выполнения этого запроса (в таблице всего 336 записей).
Как видим, в примере не используется ни один индекс. После создания индекса:
mysql> EXPLAIN SELECT * FROM users WHERE email = 'golotyuk@gmail.com';
+----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+
| 1 | SIMPLE | users | const | email | email | 386 | const | 1 | |
+----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+Прочитана всего одна запись, т.к. был использован индекс.
Проверка длинны составных индексов
Explain также поможет определить правильность использования составного индекса. Проверим запрос из примера (с индексом на колонки age и gender):
mysql> EXPLAIN SELECT * FROM users WHERE age = 29 AND gender = 'male';
+----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+
| 1 | SIMPLE | users | ref | age_gender | age_gender | 24 | const,const | 1 | Using where |
+----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+Значение key_len показывает используемую длину индекса. В нашем случае 24 байта — длинна всего индекса (5 байт age + 19 байт gender).
Если мы изменим точное сравнение на поиск по диапазону, увидим что MySQL использует только часть индекса:
mysql> EXPLAIN SELECT * FROM users WHERE age <= 29 AND gender = 'male';
+----+-------------+--------+------+---------------+------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------------+---------+------+------+-------------+
| 1 | SIMPLE | users | ref | age_gender | age_gender | 5 | | 82 | Using where |
+----+-------------+--------+------+---------------+------------+---------+------+------+-------------+Это сигнал о том, что созданный индекс не подходит для этого запроса. Если же мы создадим правильный индекс:
mysql> Create index gender_age on users(gender, age);
mysql> EXPLAIN SELECT * FROM users WHERE age < 29 and gender = 'male';
+----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+
| 1 | SIMPLE | users | range | age_gender,gender_age | gender_age | 24 | NULL | 47 | Using where |
+----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+В этом случае MySQL использует весь индекс gender_age, т.к. порядок колонок в нем позволяет сделать эту выборку.
7. Селективность индексов
Вернемся к запросу:
SELECT * FROM users WHERE age = 29 AND gender = 'male'Для такого запроса необходимо создать составной индекс. Но как правильно выбрать последовательность колонок в индексе? Варианта два:
- age, gender
- gender, age
Подойдут оба. Но работать они будут с разной эффективностью.
Чтобы понять это, рассмотрим уникальность значений каждой колонки и количество соответствующих записей в таблице:
mysql> select age, count(*) from users group by age;
+------+----------+
| age | count(*) |
+------+----------+
| 15 | 160 |
| 16 | 250 |
| ... |
| 76 | 210 |
| 85 | 230 |
+------+----------+
68 rows in set (0.00 sec)
mysql> select gender, count(*) from users group by gender;
+--------+----------+
| gender | count(*) |
+--------+----------+
| female | 8740 |
| male | 4500 |
+--------+----------+
2 rows in set (0.00 sec)
Эта информация говорит нам вот о чем:
- Любое значение колонки age обычно содержит около 200 записей.
- Любое значение колонки gender — около 6000 записей.
Если колонка age будет идти первой в индексе, тогда MySQL после первой части индекса сократит количество записей до 200. Останется сделать выборку по ним. Если же колонка gender будет идти первой, то количество записей будет сокращено до 6000 после первой части индекса. Т.е. на порядок больше, чем в случае age.
Это значит, что индекс age_gender будет работать лучше, чем gender_age.
Селективность колонки определяется количеством записей в таблице с одинаковыми значениями. Когда записей с одинаковым значением мало — селективность высокая. Такие колонки необходимо использовать первыми в составных индексах.
8. Первичные ключи
Первичный ключ (Primary Key) — это особый тип индекса, который является идентификатором записей в таблице. Он обязательно уникальный и указывается при создании таблиц:
CREATE TABLE `users` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`email` varchar(128) NOT NULL,
`name` varchar(128) NOT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8При использовании таблиц InnoDB всегда определяйте первичные ключи. Если первичного ключа нет, MySQL все равно создаст виртуальный скрытый ключ.
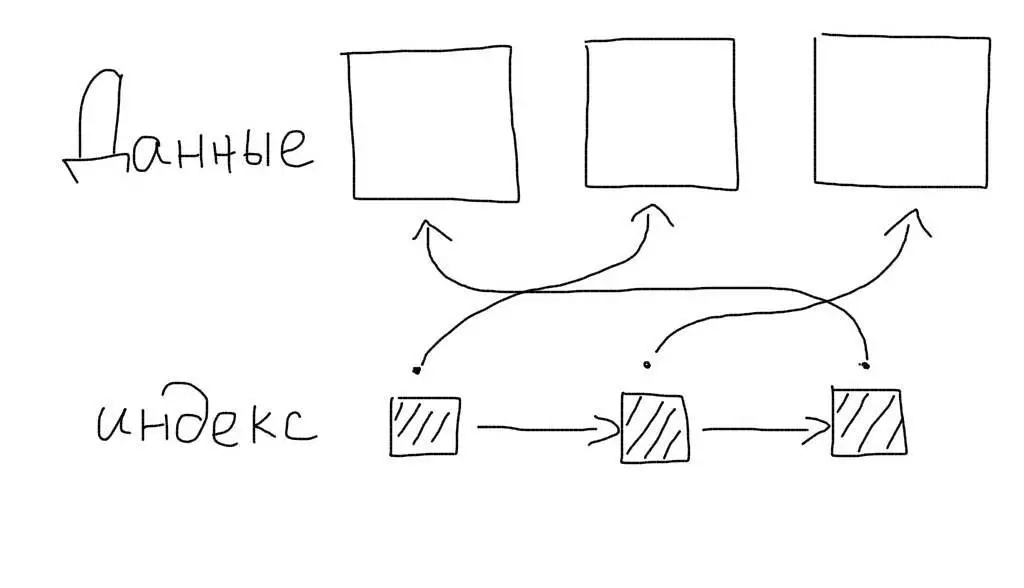
Кластерные индексы
Обычные индексы являются некластерными. Это означает, что сам индекс хранит только ссылки на записи таблицы. Когда происходит работа с индексом, определяется только список записей (точнее список их первичных ключей), подходящих под запрос. После этого происходит еще один запрос — для получения данных каждой записи из этого списка.
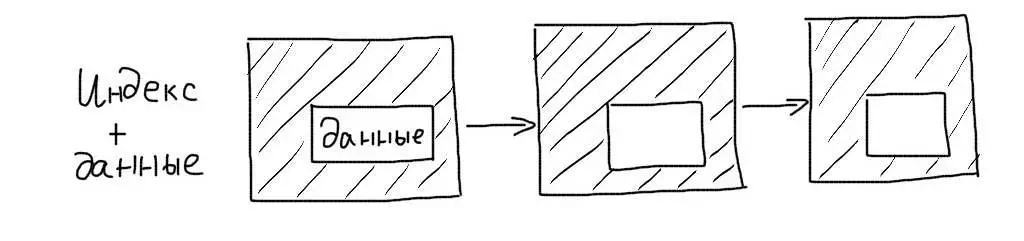
Кластерные индексы сохраняют данные записей целиком, а не ссылки на них. При работе с таким индексом не требуется дополнительной операции чтения данных.
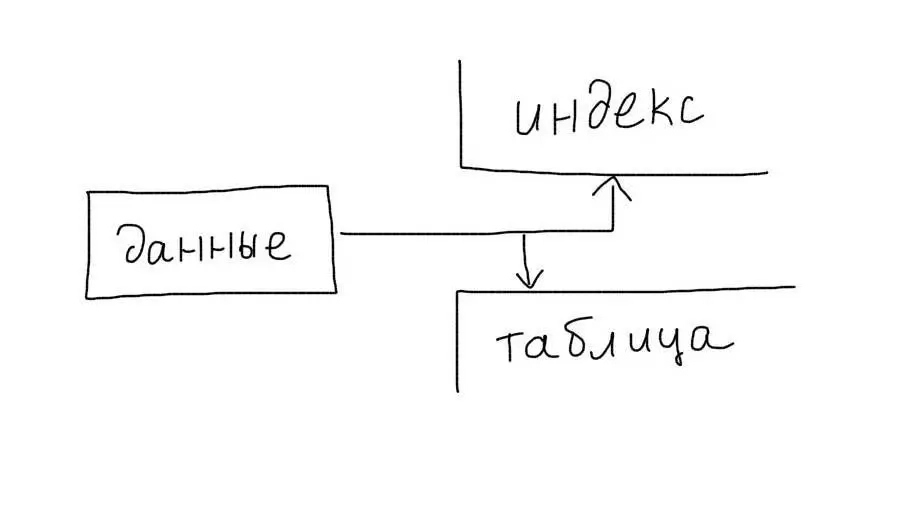
Первичные ключи таблиц InnoDB являются кластерными. Поэтому выборки по ним происходят очень эффективно.
Overhead
Важно помнить, что индексы предполагают дополнительные операции записи на диск. При каждом обновлении или добавлении данных в таблицу, происходит также запись и обновление данных в индексе.
Создавайте только необходимые индексы, чтобы не расходовать зря ресурсы сервера. Контролируйте размеры индексов для Ваших таблиц:
mysql> show table status;
+-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment |
+-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+
...
| users | InnoDB | 10 | Compact | 314 | 208 | 65536 | 0 | 16384 | 0 | 355 | 2014-07-11 01:12:17 | NULL | NULL | utf8_general_ci | NULL | | |
+-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+
18 rows in set (0.06 sec)Когда создавать индексы
- Индексы следует создавать по мере обнаружения медленных запросов. В этом поможет slow log в MySQL. Запросы, которые выполняются более 1 секунды являются первыми кандидатами на оптимизацию.
- Начинайте создание индексов с самых частых запросов. Запрос, выполняющийся секунду, но 1000 раз в день наносит больше ущерба, чем 10-секундный запрос, который выполняется несколько раз в день.
- Не создавайте индексы на таблицах, число записей в которых меньше нескольких тысяч. Для таких размеров выигрыш от использования индекса будет почти незаметен.
- Не создавайте индексы заранее, например, в среде разработки. Индексы должны устанавливаться исключительно под форму и тип нагрузки работающей системы.
- Удаляйте неиспользуемые индексы.
Самое важное
Выделяйте достаточно времени на анализ и организацию индексов в MySQL (и других базах данных). На это может уйти намного больше времени, чем на проектирование структуры базы данных. Удобно будет организовать тестовую среду с копией реальных данных и проверять там разные структуры индексов.
Не создавайте индексы на каждую колонку, которая есть в запросе, MySQL так не работает. Используйте уникальные индексы, где необходимо. Всегда устанавливайте первичные ключи.
Индексы в JOIN запросах
Представим, что у нас есть простая система подсчета статистики просмотров статей. Данные о статьях мы храним в одной таблице:
+-------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+-------------------+-----------------------------+
| id | int(11) | NO | PRI | 0 | |
| ts | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
| title | varchar(512) | YES | | NULL | |
+-------+--------------+------+-----+-------------------+-----------------------------+Данные со статистикой хранятся в другой таблице с такой структурой:
+------------+---------+------+-----+------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------+------+-----+------------+----------------+
| url_id | int(11) | NO | PRI | NULL | auto_increment |
| article_id | int(11) | NO | | 0 | |
| date | date | NO | | 0000-00-00 | |
| pageviews | int(11) | YES | | NULL | |
| uniques | int(11) | YES | | NULL | |
+------------+---------+------+-----+------------+----------------+Обратите внимание, что во второй таблице первичный ключ — это url_id. Это идентификатор ссылки на статью. Т.е. у одной статьи может быть несколько разных ссылок, и для каждой из них мы будем собирать статистику. Колонка article_id соответствует колонке id из первой таблицы. Сама статистика очень простая — количество просмотров и уникальных посетителей в день.
Выборка статистики для одной статьи
Сделаем выбор статистики для одной статьи:
SELECT s.article_id, s.date, SUM(s.pageviews), SUM(s.uniques)
FROM articles a
JOIN articles_stats s ON (s.article_id = a.id)
WHERE a.id = 4
GROUP BY s.date;# Статистика для статьи с id = 4
На выходе получим просмотры и уникальных посетителей для этой статьи за каждый день:
+------------+------------+------------------+----------------+
| article_id | date | SUM(s.pageviews) | SUM(s.uniques) |
+------------+------------+------------------+----------------+
| 4 | 2016-01-03 | 28920 | 9640 |
... ...
| 4 | 2016-01-07 | 1765 | 441 |
+------------+------------+------------------+----------------+
499 rows in set (0.37 sec)Запрос отработал за 0.37 секунд, что довольно медленно. Посмотрим на EXPLAIN:
+----+-------------+-------+-------+---------------+---------+---------+-------+--------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+--------+----------------------------------------------+
| 1 | SIMPLE | a | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | s | ALL | NULL | NULL | NULL | NULL | 676786 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+-------+--------+----------------------------------------------+EXPLAIN показывает две записи — по одной для каждой таблицы из нашего запроса:
- Для первой таблицы Mysql выбрал индекс PRIMARY и эффективно его использовал.
- Для второй таблицы Mysql не смог найти подходящих индексов и ему пришлось проверить почти 700 тыс. записей, чтобы сгенерировать результат.
В JOIN запросах Mysql будет использовать индекс, который позволит отфильтровать больше всего записей из одной из таблиц
Поэтому нам необходимо убедиться, что Mysql будет быстро выполнять запрос такого вида:
SELECT article_id, date, SUM(pageviews), SUM(uniques) FROM articles_stats WHERE article_id = 4 GROUP BY dateСогласно логике выбора индексов построим индекс по колонке article_id:
CREATE INDEX article_id on articles_stats(article_id);Проверим использование индексов в нашем первом запросе и увидим, что Mysql теперь использует индексы для двух таблиц:
+----+-------------+-------+-------+---------------+------------+---------+-------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------------+---------+-------+------+----------------------------------------------+
| 1 | SIMPLE | a | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | s | ref | article_id | article_id | 4 | const | 677 | Using where |
+----+-------------+-------+-------+---------------+------------+---------+-------+------+----------------------------------------------+Это значительно ускорит запрос (ведь Mysql во втором случае обрабатывает в 1000 раз меньше данных).
Агрегационные запросы
Предыдущий пример носит более лабораторный характер. Более приближенный к практике запрос — это выборка статистики сразу по нескольким статьям:
SELECT s.article_id, s.date, SUM(s.pageviews), SUM(s.uniques), a.title, a.ts
FROM articles a
JOIN articles_stats s ON (s.article_id = a.id)
WHERE a.id IN (4,5,6,7)
GROUP BY s.date;Однако в этом случае Mysql будет вести себя точно также. Он оценит какие индексы можно использовать из каждой таблицы. EXPLAIN покажет:
+----+-------------+-------+--------+---------------+------------+---------+-------------------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+------------+---------+-------------------+------+----------------------------------------------+
| 1 | SIMPLE | s | range | article_id | article_id | 4 | NULL | 2030 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | Using index |
+----+-------------+-------+--------+---------------+------------+---------+-------------------+------+----------------------------------------------+Таблицы будут обработаны в другом порядке. Сначала будет сделана выборка всех подходящих значений из таблицы статистики. А затем из таблицы с названиями.
Mysql решил, что сначала выбрав статистику по всем нужным статьям, он затем быстрее сделает выборку из таблицы articles. Порядок в этом случае не имеет особого значения, ведь в таблице articles выборка происходит по первичному ключу.
Дополнительные фильтры
На практике приходится иметь дело с дополнительными фильтрами в запросах. Например, выборка статистики только за определенную дату:
SELECT s.article_id, s.date, SUM(s.pageviews), SUM(s.uniques), a.title, a.ts
FROM articles a
JOIN articles_stats s ON (s.article_id = a.id)
WHERE s.date = '2017-05-14'
GROUP BY article_idВ этом случае, Mysql снова не сможет подобрать индекс для таблицы статистики:
+----+-------------+-------+--------+---------------+---------+---------+-------------------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+--------+-------------+
| 1 | SIMPLE | s | ALL | article_id | NULL | NULL | NULL | 676786 | Using where |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+--------+-------------+Логика выбора индекса тут такая же, как и в предыдущем примере. Необходимо подобрать индекс, который позволит быстро отфильтровать таблицу статистики по дате:
CREATE INDEX date ON articles_stats(date);Теперь запрос будет использовать индексы на обе таблицы:
+----+-------------+-------+--------+-----------------+---------+---------+-------------------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+-----------------+---------+---------+-------------------+------+----------------------------------------------+
| 1 | SIMPLE | s | ref | article_id,date | date | 4 | const | 2996 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | |
+----+-------------+-------+--------+-----------------+---------+---------+-------------------+------+----------------------------------------------+Сложные фильтры и сортировки
В еще более сложных случаях выборки включают дополнительные фильтры либо сортировки. Допустим, мы хотим выбрать все статьи, созданные не позднее месяца назад. А статистику показать для них только за последний день. Только для тех публикаций, у которых набрано более 15 тыс. уникальных посещений. И результат отсортировать по просмотрам:
SELECT s.article_id, s.date, SUM(s.pageviews), SUM(s.uniques), a.title, a.ts
FROM articles a
JOIN articles_stats s ON (s.article_id = a.id)
WHERE a.ts > '2017-04-15' AND s.date = '2017-05-14' AND s.uniques > 15000
GROUP BY article_id
ORDER BY s.pageviews# Запрос отработает за 0.15 секунд, что довольно медленно
Mysql будет искать индексы, которые позволят отфильтровать максимум значений из каждой исходной таблицы. В нашем случае это будут:
+----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+
| 1 | SIMPLE | s | range | date | date | 4 | NULL | 26384 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | Using where |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+Индекс date позволит отфильтровать таблицу статистики до 26 тыс. записей. Каждую из которых придется проверить на соответствие другим условиям (количество уникальных посетителей более 15 тыс.).
Сортировку по просмотрам Mysql будет в любом случае делать самостоятельно. Индексы тут не помогут, т.к. сортируем динамические значения (результат операции GROUP BY).
Поэтому наша задача — выбрать индекс, который позволит максимально сократить выборку по таблице articles_stats используя фильтр s.date = '2017-05-14' AND s.uniques > 15000.
Создадим индекс на обе колонки из первого пункта:
CREATE INDEX date_uniques ON articles_stats(date,uniques);Тогда Mysql сможет использовать этот индекс для фильтрации таблицы статистики:
+----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+
| 1 | SIMPLE | s | range | date_uniques | date_uniques | 9 | NULL | 1681 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | a | eq_ref | PRIMARY,ts_id | PRIMARY | 4 | test.s.article_id | 1 | Using where |
+----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+# При таком индексе Mysql обработает в 10 раз меньше записей для выборки
Другие стратегии ускорения JOIN
В ситуациях, когда невозможно выбрать подходящий индекс, следует подумать о денормализации. В этом случае стоит пользоваться правилом:
Лучше много легких записей, чем много тяжелых чтений
Следует создать таблицу, оптимизированную под запрос и синхронно её обновлять. Однако убедитесь, что ваш сервер хорошо настроен. В качестве срочных мер рассмотрите возможность кешировать результаты тяжелых запросов.