SSL / ESI / Кэширование публичного веб-приложения
Публичное веб-приложение должно индексироваться поисковыми системами, которым очень важны следующие показатели:
- TTFB: Time to First Bite — время от начала запроса до получения первого байта
- TTLB: Time to Last Bite — время от начала запроса до получения последнего байта
Поэтому, предварительное создание/обновление/удаление документом видится разумным решением.
Представления
Представление публичного веб-приложение глобально можно разделить на 2 вида:
- для неаутентифицированного пользователя: например для поисковых роботов
- для аутентифицированных пользователей: представление для пользователей
Самый простой способ понять вид представления - проверять признак аутентификации, например:
- заголовок с OAUTH токеном
- наличие записи в COOKIE-заголовка
- и т.п.
Если приложение имеет большой трафик для неаутентифицированного пользователя, то документы приложения лучше создавать предварительно (до того, как клиент запросит такой документ).
Роли представления для неаутентифицированного пользователя
В предварительной обработке представления для неаутентифицированного пользователя можно выделить 2 роли:
- Агрегатор документов - приложение хранящее актуальные документы всех владельцев документов
- Владелец документов - приложение получающее бизнес-события (EDA), изменяющее свое состояние и уведомляющее Агрегатора о создании/обновлении/удалении статичных документов (в виде адрес : документ)
Генерация документов для поисковых роботов
Т.к. поисковые роботы при индексировании используют только GET-запросы, то условно документы для неаутентифицированного пользователя, можно разделить на 2 типа:
- заранее известные - документы с заранее известными GET-параметрами в адресе
- заранее неизвестные - документы с заранее неизвестными GET-параметрами в адресе
Заметки:
- заранее неизвестные документы обычно мы видим по мере работы клиента с приложением, например клиент использует фильтрацию посредством отправки данных в приложение, что в свою очередь порождает адреса документов в которых имеются GET-переменные
- все адреса заранее неизвестного документа можно сгенерировать, но иногда этого делать не нужно, т.к. во первых это очень затратно по ресурсам, а во вторых один вариант представления может не сильно отличаться от второго (а иногда и совсем не отличаться, например фильтрация + пагинация, когда отличие видно только на определенной странице пагинации)
- отсюда следует, что при необходимости, мы можем наращивать кол-во заранее известных документов из заранее неизвестных, таким образом все остальные документы делая неиндексирумыми

Кэширование для аутентифицированного пользователя
Частичное кэширование можно реализовать с помощью инструмента Varnish + ESI-блоков, коротко принцип работы:
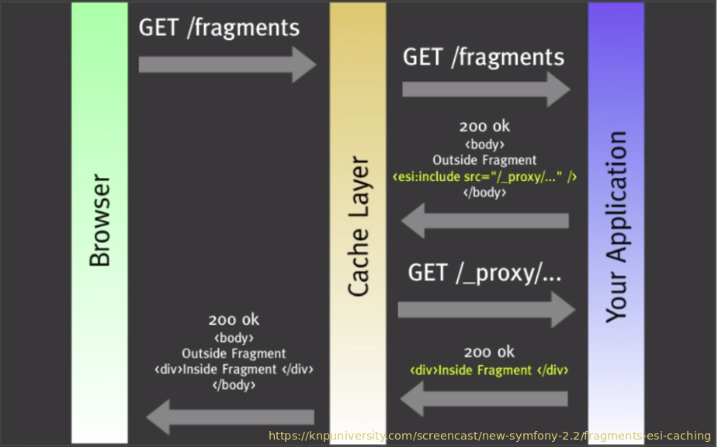
Сначала пользователь посылает запрос на получение ресурса. Если в теле ответа содержатся специальные теги <esi:include src="/..." />, кэширующий сервер запрашивает бэкенд для получения дополнительных блоков контента.
Varnish представляет собой кеширующий “обратный” (reverse) прокси-сервер и акселератор HTTP. Принцип его работы: получает запрос, обрабатывает его и сразу выдает ответ если он присутствует в кэше, если нет то обращается к веб-серверу за результатом. Ответ помещается в кэш. Многопоточность реализована с помощью стандартных потоков POSIX, их количество регулируется. Это одна из причин почему Varnish не очень хорошо работает в Windows. Каждый запрос обрабатывается в отдельном потоке. Причем с версии 4.0 за получение запроса от пользователя и передача запроса серверу отвечают разные потоки, что еще более повысило производительность. Varnish поддерживает технологию ESI (Edge Side Includes) позволяющую разбивать веб-страницу на части и запрашивать их отдельно. Кэш может хранить любую информацию. В итоге Varnish отлично подходит для кэширования динамического контента.
Для хранения данных (кэша, журналов операций) используется виртуальная память, управлением того что выгружается на диск занимается ОС. Здесь авторы Varnish справедливо считают, что разработчики ОС свое дело знают, а дублирование только ухудшает производительность.
Варианты реализации ESI
Реализации ESI сильно различаются от одного ПО к другому, вот сравнение:
| Software | Includes | Vars | Cookies | Upstream Headers Required | Host Whitelist |
|---|---|---|---|---|---|
| Squid3 | Yes | Yes | Yes | Yes | No |
| Varnish Cache | Yes | No | No | Yes | Yes |
| Fastly | Yes | No | No | No | Yes |
| Akamai ESI Test Server (ETS) | Yes | Yes | Yes | No | No |
| NodeJS’ esi | Yes | Yes | Yes | No | No |
| NodeJS’ nodesi | Yes | No | No | No | Optional |
Столбцы таблицы описываются следующим образом:
- Includes - в этом столбце указано
<esi:includes>, реализован ли операнд в механизме ESI. - Vars - в этом столбце указано
<esi:vars>, реализован ли операнд в механизме ESI. - Cookies - в этом столбце указано, доступны ли файлы cookie для механизма ESI.
- Upstream Headers Required - в этом столбце указывается, требуются ли восходящие заголовки для работы ESI. Если заголовки не предоставлены вышестоящим сервером приложений, суррогат не будет обрабатывать операторы ESI.
- Host Whitelist (белый список хостов) - если включены ESI, обработка документов возможна только для хостов серверов из белого списка. Когда это верно, включения ESI не могут использоваться для выполнения SSRF на хостах, отличных от тех, которые внесены в белый список.
Подробное сравнение рассматривается тут (pdf)
В отличие от Squid который изначально больше ориентировался на кэширование клиентских запросов, Varnish был разработан и оптимизирован именно в качестве ускорителя HTTP и ничего другого больше не умеет. Мы не найдем здесь поддержку остальных протоколов (FTP, SMTP и прочие), не увидим возможности прямого прокси — кэширования веб-страниц для экономии внешнего трафика (Varnish «привязывается» к бэкэндам). Естественно отличается и возможности по конфигурированию.
Язык конфигурации Varnish Configuration Language (VCL) — динамический, скрипт сам по себе по сути является отдельным плагином. Код транслируется в С (можно сразу писать встраиваемый код на С), после чего инструкции компилируются в библиотеку и подгружаются в память. Можно вносить изменения в конфигурацию «на лету». Инструкции в VCL позволяют: кэшировать только определенные запросы, снижая нагрузку при генерации динамических объектов, блокировать доступ к определенным каталогам и скриптам, подменять заголовки и многое другое. Есть и механизм проверки работоспособности бэкендов (замер времени ответа, счетчик неудачных проверок и т.д.), возможность перезаписи и перенаправления (rewrite) запросов. Вообще такой подход позволяет производить с HTTP трафиком практически любые манипуляции, которые можно ограничить только собственным воображением. Поддерживается балансировка нагрузки несколько алгоритмов (round robin, random и DNS, Client IP). Возможности расширяются при помощи модулей, называемых VMOD (Varnish MODules). Проект предоставляет необходимую документацию позволяющих написать такой модуль самостоятельно. Часть модулей (varnish-cache.org/vmods) уже включены в стандартную поставку, некоторые доступны в виде концепта или находятся в разработке.
Терминология
Rendering
- SSR: Server-Side Rendering — рендеринг клиентского или универсального приложения в HTML на сервере.
- CSR: Client-Side Rendering — рендеринг приложения в браузере, обычно с использованием модели DOM.
- Rehydration: «загрузка» представлений JavaScript на клиенте таким образом, чтобы они повторно использовали дерево и данные DOM HTML, отображаемые на сервере.
- Prerendering: запуск клиентского приложения во время сборки для фиксации его исходного состояния в виде статического HTML.
Performance
- FP: First Paint — первый раз, когда любой пиксель становится видимым для пользователя.
- FCP: First Contentful Paint — время, когда запрошенный контент (тело статьи и т. д.) становится видимым.
- TTI: Time To Interactive — время, когда страница становится интерактивной (события подключены и т. д.).
Заметка: нельзя полагаться на то, что клиент будет что-то кэшировать, поэтому нет особого смысла использовать HTTP-заголовки кэширования