Стратегии решения базовых проблем
Graceful Degradation Pattern
Говорит о том, что мы можем постепенно уменьшать функционал сервиса до минимального, а если нет возможности реализовывать минимальный функционал, то показываем 500 и ограничиваем трафик
Ограничение количества неудачных запросов от клиента к сервису
Установите лимит максимального количества неудавшихся запросов, которые клиент может послать определенному сервису. При исчерпании этого лимита выполнение дальнейших запросов, скорее всего, будет бессмысленным, поэтому такие попытки должны сразу завершаться ошибкой.
Раундробин
Чтобы обработать большое количество запросов используют балансировщик распределяя запросы раундробином по нодам.
Стеки запросов (почти бесполезно)
Раундробин не поможет, если ресурсы закончатся у нод в результате высокой нагрузки, ведь тогда нода не успевает обрабатывать запросы.
Вместо раундробин используют стеки запросов на балансировщике, который знает о мощностях каждой ноды. В результате если нода способна обслужить 100 запросов, то 101-ый запрос сразу будет отброшен.
Минус в том, что 100 запросов могут быть легковесными, а могут быть тяжеловесными, так что это плохая стратегия.
Дедлайн (тайм-аут на запрос)
Клиенты не могут долго ждать ответа от сервера, поэтому используют тайм-ауты как на клиенте, так и на сервере:
- дедлайн устанавливаемый клиентом, который не может превышать дедлайн установленный в балансировщике/сервисах
- дедлайн на сервере (тайм-аут на запрос в рамках каждого балансировщика/сервисах)
Ввод в эксплуатацию еще одного инстанса: при добавлении к кластеру нагрузки повышайте ее уровень медленно. Небольшое количество запросов на начальном этапе разогреет кэш. Как только он прогреется, можете добавить трафика.
Сетевое время ожидания: никогда не блокируйтесь бессрочно, всегда отсчитывайте время ожидания запроса. Это гарантирует, что когда-нибудь ресурсы освободятся.
Шаблон «Предохранитель» (Circuit Breaker Pattern)
Circuit Breaker выступает как прокси-сервис между приложением и удаленным сервисом.
Данный паттерн может быть реализован по-разному, рассмотрим варианты.
1. Отслеживайте количество успешных и неудавшихся запросов. Если частота ошибок превысит некий порог, разомкните предохранитель, чтобы дальнейшие попытки сразу же завершались. Большое количество неудачных запросов говорит о том, что сервис недоступен и обращаться к нему не имеет смысла. По истечении какого-то периода клиент должен предпринять новую попытку и, если она окажется успешной, замкнуть предохранитель.
2. Некая программа отслеживает здоровье всех экземпляров сервиса B, и если экземпляр не здоров, отключает трафик к нему.
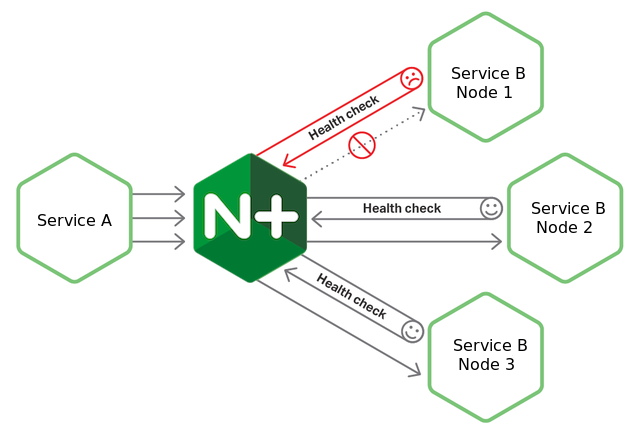
Если все экземпляры не здоровы, то весь трафик к сервису B отключается. Считается, что это позволяет дать время экземплярам сервера B для того, чтобы выздороветь. В это время сервис B может полагаться только на себя (например на свой кэш):
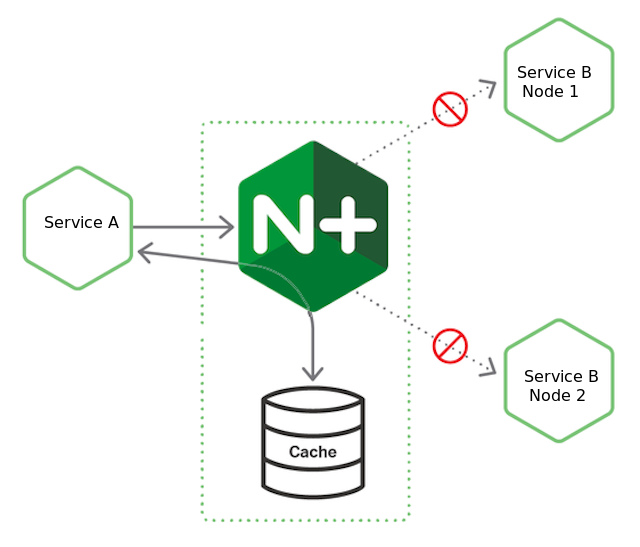
а) В nginx-plus можно включать данный патерн и описывает реализацию так:
Circuit Breaker достигается за счет того, что веб-служба сигнализирует о том, что она неработоспособна, а прерыватель цепи затем дает службе возможность восстановиться, ограничивая количество запросов или полностью перенаправляя их. После восстановления службы прерыватель цепи также имеет смысл медленно наращивать запросы к службе, чтобы не перегрузить ее сразу и не рисковать, что она снова станет неработоспособной.
так же есть информация про Netflix, а еще есть библиотека:
б) Netflix Hystrix (github.com/Netflix/Hystrix) — это библиотека с открытым исходным кодом, которая реализует эти и другие шаблоны. Если вы работаете с JVM, вам определенно стоит подумать об использовании Hystrix при реализации RPI-прокси. Если же имеете дело со средой, не основанной на JVM, следует применять аналогичную библиотеку. Например, в сообществе .NET популярен проект Polly (github.com/App-vNext/Polly).
Дополнительно по Circuit Breaker
У него есть 3 состояния:
1) Closed: запрос от приложения направляется напрямую к сервису. Счетчик ошибок = 0 и приложение спокойно функционирует и шлет запросы направо и налево. Все счастливы. Прокси-сервис увеличивает счетчик ошибок, если операция завершилась неуспешно. Если количество ошибок за некоторый промежуток времени превышает заранее
заданный порог значений, то прокси-сервис переходит в состояние Open и запускает таймер времени ожидания. Когда таймер истекает, он переходит в состояние Half-Open. Назначение таймера — дать сервису время для решения проблемы, прежде чем
разрешить приложению попытаться выполнить операцию еще раз.
2) Open: запрос от приложения немедленно завершает с ошибкой и исключение возвращается в приложение.3) Half-Open: ограниченному количеству запросов от приложения разрешено обратиться к сервису. Если эти запросы успешны, то считаем что предыдущая ошибка исправлена и прокси-сервис переходит в состояние Closed (счетчик ошибок сбрасывается на 0). Если любой из запросов завершился ошибкой, то считается, что ошибка все еще присутствует, тогда прокси-сервис возвращается в состояние Open и перезапускает таймер, чтобы дать системе дополнительное время на восстановление после сбоя. Состояние Half-Open помогает предотвратить быстрый рост запросов к сервису. Т.к. после начала работы сервиса, некоторое время он может быть способен обрабатывать ограниченное число запросов до полного восстановления.
Шаблон Circuit Breaker обеспечивает стабильность, пока система восстанавливается после сбоя и снижает влияние на производительность. Благодаря этому можно поддерживать определенный показатель времени отклика системы, быстро отклоняя запрос на операцию, которая, скорее всего, завершится со сбоем, вместо того чтобы ждать, пока не истечет время ожидания операции или ждать в течение неопределенного времени (так как операция никогда не возвратится).
Пример
Возьмем пример с оплатой картой:проверяем, в каком состоянии circuit breaker если закрыт (Closed), то отправляем запрос на сервер, делаем попытку оплаты, все хорошо и все счастливы если произошла ошибка, то переводим в состояние Open, запускаем таймер и показываем ошибку следующий раз, когда будем слать запрос, состояние уже не Closed, а Open, то мы
проверяем тот самый таймер (таймер — это то время, которое мы даем серверу на восстановление). Если он не истек, т.е. эта условная скажем минута еще не прошла, то мы на клиенте завершаемся с ошибкой, которая была в предыдущем запросе.
Если таймер истек — пробуем оплатить, все хорошо — переводим в состояние Closed, выключаем таймер и завершаем оплату заказа. Если все плохо — то возвращаемся на шаг Open.
Эта часть хорошо комбинируется с паттерном Retry, ведь не после каждой ошибки стоит блокировать, например если ошибка кратковременного характера (как уже говорилось ранее), можем попробовать отправить запрос еще раз, несколько попыток и
только потом переводить в состояние счетчика.
Какой можем сделать вывод?
Паттерн Circuit Breaker добавляет стабильности, когда система восстанавливается после падения и минимизирует влияние этого падения на производительность. Можно отслеживать события перехода по статусу для мониторинга и уведомления
администраторов о возникшей ошибке.
Когда стоит использовать?
- Для предотвращения попыток обращения к сервису или разделяемым ресурсам, когда вероятность возникновения ошибки высока и эти ошибки имеют продолжительный характер.
Когда не стоит использовать?
- Для обращения к приватным ресурсам приложения — это даст только дополнительный overhead.
- Как замена обработки исключений бизнес-логики приложения.
Мониторинг
Использовать мониторинг и алертинг приложения из вне компании
Удаление данных
Копить данные которые нужно удалять, а затем удаляю их в рамках одного процесса (как можно быстрее). Полезнее будет оповещать о том, что выполняется удаление большого количества данных, собранных для всех пользователей, которое превышает определенную границу (например, 10х от наблюдаемого 95-го процентиля), чем удалять маленькими незаметными порциями, которые за большой промежуток времени невозможно восстановить.
Чеклисты
Чтобы ничего не забыть, нужно создавать чеклисты на повторяемые действия, будь то запуск нового сервиса, нового инфраструктурного решения или просто деплой на прод.
Проводить DiRT испытания
...
Idempotency Key
Решает проблему, когда при "покупке товара" / "оплате банковской картой" Вы отправили 2 запроса на оплату товара и они оба выполнились успешно (это неприятно). Как решает: каждый наш запрос из сервиса А мы снабжаем ключем, подписываем, говорим сервису B что вот этот запрос наш и у него такой вот идентификатор. Сервис B перед тем как выполнить запрос складывает его в базу и помечает, что вот этот запрос он сейчас обрабатывает. В итоге 2 одинаковых ключа мы положить не
можем в БД => мы можем быть уверены, что наш запрос выполнится единожды.
Retry pattern
Мы будем переотправлять запрос до тех пор, пока он не окажется успешным. Если пользователь ввел неверные данные карты, то сколько бы мы не пробовали раз повторить, то все равно не получится совершить удачный запрос. Если исчерпали
какое-то кол-во попыток,то не стоит пробовать отправлять дальше до бесконечности. Стратегии ожидания бывает следющие:
- без ожидания (no delay), когда сразу без паузы повторяем отправку запроса
- с константным значением (constant), когда устанавливаем строго заданный лимит
- с линейным значением (linear)
- с экспоненциальным значением (exponencial)
В каких случаях стоит использовать Retry паттерн ?
- Когда в вашем приложении при работе с удаленным сервисом могут возникнуть временные ошибки. Эти ошибки имеют кратковременный характер и высока вероятность того, что следующие запросы будут завершены успешно (Временная
недоступность сервиса или тайм-ауты из-за пиковой нагрузки на сервис).
Когда не стоит использовать данный паттерн ?
- Когда ошибки имеют долговременный характер, и приложение будет бесполезно тратить ресурсы на попытки повторить операции (в этом случае стоит задуматься об использовании Circuit Breaker).
- Для обработки ошибок связанных с бизнес-логикой приложения
- Если сервис слишком часто сигнализирует о том, что он “занят”, то скорее всего он требует больше ресурсов
Комментарии