IMDG - In-Memory Data Grids
В последнее время обработка в памяти была довольно горячей темой. Многие компании, которые раньше не рассматривали возможность использования технологии in-memory, поскольку это было непомерно дорого, теперь меняют архитектуру своих основных систем, чтобы воспользоваться преимуществом обработки транзакций с малой задержкой, которую предлагает технология in-memory. Это является следствием того, что цена на оперативную память значительно и быстро снижается, и в результате стало экономически выгодно загружать весь набор операционных данных в память с повышением производительности более чем в 1000 раз быстрее. Вычисления в памяти и сети данных обеспечивают основные возможности архитектуры в памяти.
Цель In-Memory Data Grids ( IMDG ) — обеспечить чрезвычайно высокую доступность данных, сохраняя их в памяти и в высокораспределенном (т. е. распараллеленном) виде. Загружая терабайты данных в память, IMDG могут работать с большинством современных требований к обработке больших данных .
Что такое сетка данных в памяти?
Сетка данных в памяти (IMDG) — это распределенное хранилище объектов, похожее по интерфейсу на типичную параллельную хеш-карту. Вы храните объекты с ключами. В отличие от традиционных систем, где ключи и значения часто ограничены байтовыми массивами или строками, с IMDG вы можете использовать любой объект домена как значение или ключ. Это дает невероятную гибкость, позволяя хранить точно такой же объект, с которым имеет дело ваша бизнес-логика, в Data Grid без дополнительного шага маршалинга и демаршалинга, который потребовался бы альтернативными технологиями. Это также упрощает использование сетки данных, поскольку в большинстве случаев вы можете взаимодействовать с распределенным хранилищем данных, как с простой хэш-картой. Возможность напрямую работать с объектами домена является одним из основных различий между IMDG и базой данных в памяти (IMDB). С последним,
В IMDG также есть некоторые другие функции, которые отличают их от других продуктов, таких как базы данных NoSql, IMDB или базы данных NewSql. Одним из основных отличий будет действительно масштабируемое разделение данных.по кластеру. По сути, IMDG в чистом виде можно рассматривать как распределенные хэш-карты, в которых каждый ключ кэшируется на конкретном узле кластера — чем больше кластер, тем больше данных вы можете кэшировать. Хитрость этой архитектуры заключается в том, чтобы убедиться, что вы совмещаете свою обработку с узлами кластера, где данные кэшируются, чтобы убедиться, что все операции кэширования становятся локальными и что перемещение данных внутри кластера отсутствует (или минимально). На самом деле, при использовании хорошо спроектированных IMDG не должно быть абсолютно никакого перемещения данных в стабильных топологиях — единственный раз, когда некоторые данные перемещаются, — это когда новые узлы присоединяются или некоторые существующие узлы уходят, что приводит к некоторому перераспределению данных внутри кластера. .
На рисунке ниже показан классический IMDG с набором ключей {k1, k2, k3}, где каждый ключ принадлежит разным узлам. Компонент внешней базы данных является необязательным. Если они присутствуют, то IMDG обычно автоматически считывают данные из базы данных или записывают в нее данные.
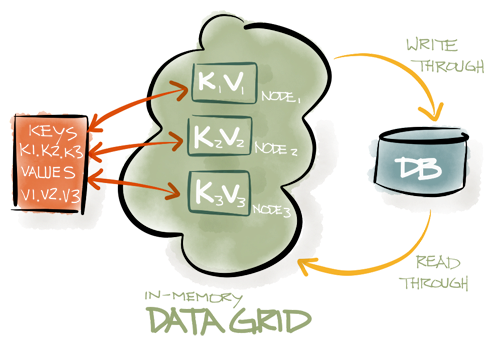
Другой отличительной чертой IMDG является поддержка Transactional ACID . Обычно протокол двухфазной фиксации ( 2PC ) используется для обеспечения согласованности данных в кластере. Разные IMDG будут иметь разные базовые механизмы блокировки, но, как правило, более продвинутые реализации обеспечивают механизмы параллельной блокировки (например, MVCC — управление параллельным доступом к нескольким версиям) и сводят к минимуму сетевую болтовню, тем самым гарантируя согласованность транзакций ACID с очень высокой производительностью.
Согласованность данных — одно из основных различий между базами данных IMDG и NoSQL. Базы данных NoSQL обычно разрабатываются на основе подхода Eventual Consistency (EC), когда данные могут быть несогласованными в течение определенного периода времени, пока они не станут согласованными *в конечном итоге*. Как правило, запись в системах на основе EC выполняется несколько быстро, а чтение — медленно (или, если быть точнее, так же быстро, как и запись). Последние IMDG с *оптимизированным* 2PC должны как минимум соответствовать, если не превосходить системы на основе EC при записи, и быть значительно быстрее при чтении. Интересно отметить, что отрасль сделала полный круг, перейдя от тогдашнего медленного подхода 2PC к подходу EC, а теперь от EC к *оптимизированному* 2PC, который зачастую значительно быстрее.
Разные продукты обеспечивают разные оптимизации 2PC, но, как правило, целью всех оптимизаций является увеличение параллелизма, минимизация сетевых издержек и уменьшение количества блокировок, необходимых для завершения транзакции. Например, распределенная глобальная база данных Google, Spanner, основана на транзакционном подходе 2PC просто потому, что 2PC обеспечивает более быстрый и простой способ гарантировать согласованность данных и высокую пропускную способность по сравнению с MapReduce или EC.
Несмотря на то, что IMDG обычно имеют некоторые общие базовые функции, многие функции и детали реализации различаются у разных поставщиков. При оценке продукта IMDG обратите внимание на политику вытеснения, методы (предварительной) загрузки, одновременное перераспределение, непроизводительные затраты памяти и т. д. Также обратите внимание на возможность запрашивать данные во время выполнения. Некоторые IMDG, такие как GridGain, например, позволяют пользователям запрашивать данные в памяти, используя стандартный SQL, включая поддержку распределенных соединений, что довольно редко.
Типичное использование IMDG — разделение данных по кластеру и последующая отправка совмещенных вычислений на узлы, где находятся данные. Поскольку вычисления обычно являются частью Compute Grid и должны быть правильно развернуты, сбалансированы по нагрузке, перенесены при отказе или запланированы, интеграция между Compute Grid и IMDG очень важна. Это особенно выгодно, если и вычисления в памяти, и сетки данных являются частью одного продукта и используют одни и те же API, что устраняет необходимость интеграции и обычно обеспечивает максимальную производительность и надежность систем.
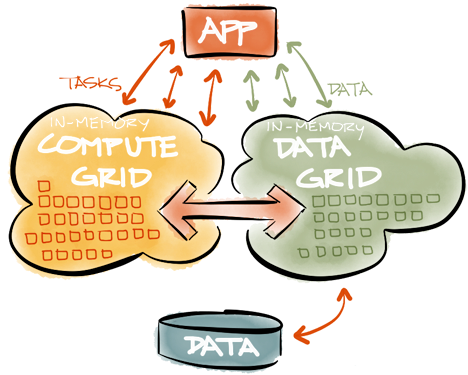
IMDG (вместе с Compute Grids) используются в широком спектре отраслей в таких разнообразных приложениях, как анализ рисков, торговые системы, биоинформатика, электронная коммерция или онлайн-игры. По сути, каждый проект, который борется с масштабируемостью и производительностью, может извлечь выгоду из обработки в памяти и архитектуры IMDG.
Источник: 1