Структуры и алгоритмы
Часто на собеседованиях могут спрашивать про структуры данных и алгоритмы работы с данными, по большому счету спрашивают лишь про некоторые из них, о которых и будет рассказано ниже.
Для начала, предлагаю рассмотреть разновидности структур данных (еще их называют ассоциативные контейнеры):
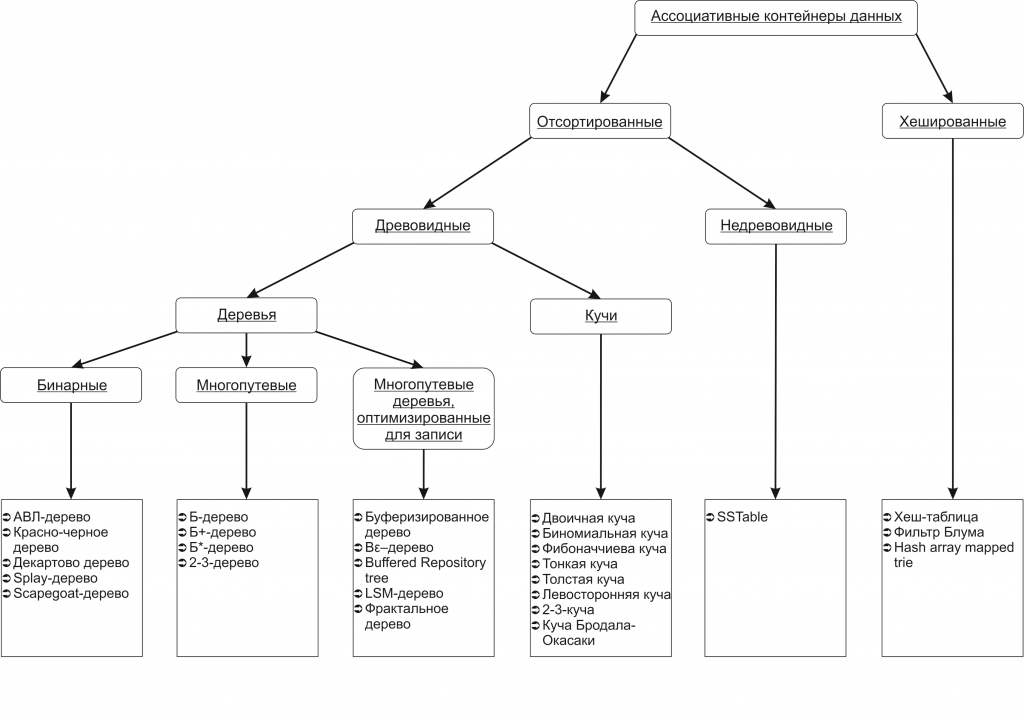
Бинарное дерево
Как видите, почти все структуры используют древовидную структуру, поэтому стоит рассмотреть для начала самое обычное бинарное дерево.
Очень важно: справа на изображении показан стек (неассоциативный массив), это реальное представление дерева (именно так линейно и хранятся значения).
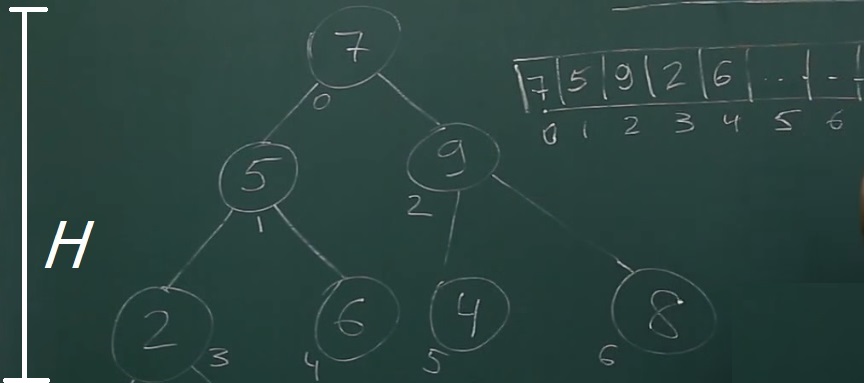
Обратите внимание на H - высота дерева.
Теперь познакомимся с формулами, которые показывают, как быстро работать с бинарным деревом. Заметим, что:
- на каждом ниже лежащем уровне, элементов вдвое больше
- номер потомка увеличивается вдвое по сравнению с его родителем.
Найти левый дочерний элемент можно по формуле: 2*i+1
Например рассмотрим элемент 1 (со значением 5): 2*1+1=3 (значение 2)
Найти правый дочерний элемент можно по формуле: 2*i+2
Например рассмотрим элемент 1 (со значением 5): 2*1+2=4 (значение 4)
Найти номер родителя можно по формуле: (i-1)%2
Например рассмотрим элемент 5 (со значением 4): (5-1)%2 =2 (значение 9)
Найти приблизительное кол-во элементов в дереве можно с помощью формулы: N ≈ 2H
Найти приблизительную высоту дерева можно с помощью формулы: H ≈ log N
Например, для выше указанного дерева H ≈ log 8 = √8 ≈ 2.8 и округляя получаем 3, проверим: 23 = 8
Время требуемое, чтобы создать дерево ≈ N log N
Забегая вперед хочется отметить, что кроме однопутевого бинарного дерева бывают еще многопутевые деревья (в которых вершины состоят из списка значений), реальный пример:
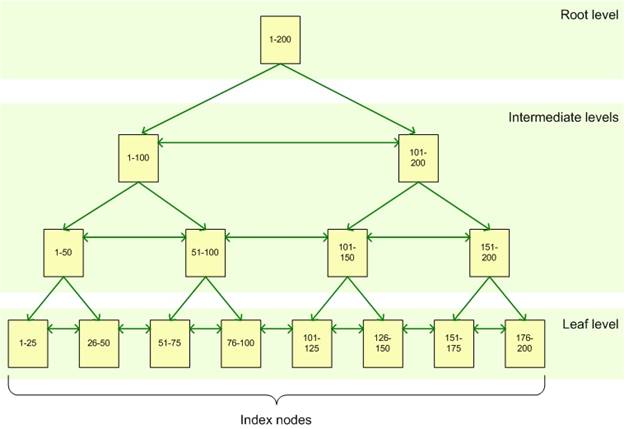{kind=link}
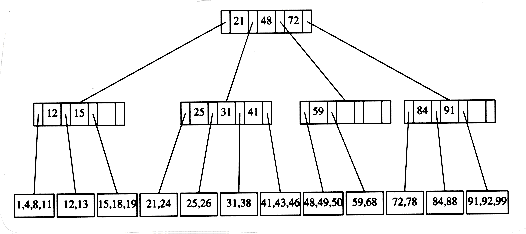{kind=link}
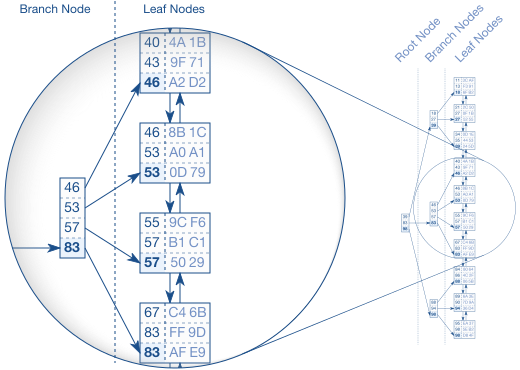
Вот как выполняется поиск в таком дереве (например поиск значения 57):
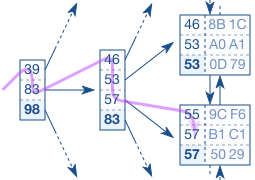
Говорят, часто в базах данных используют именно такую структуру, и в реальности глубина такого дерева часто не превышает 5.
Пожалуй, это все, что Вас могут спросить на собеседовании, но иногда еще спрашивают про связанный список (советю почитать 1 и 2 ).
А для более любознательных, я припас статью о всех выше перечисленных структурах (копия) и стоит заметить, что SSTable это Кортеж, но не фиксированной длинны.
Двусвязный список (двунаправленный связный список)
Здесь ссылки в каждом узле указывают на предыдущий и на последующий узел в списке.
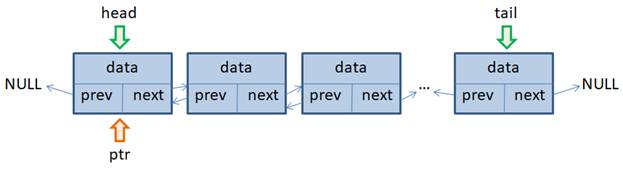
Как и односвязный список, двусвязный допускает только последовательный доступ к элементам, но при этом дает возможность перемещения в обе стороны. В этом списке проще производить удаление и перестановку элементов, так как легко доступны адреса тех элементов списка, указатели которых направлены на изменяемый элемент.
В пхп используют именно его, вот детали.
Сортировка пузырьком
Хоть и описана в Wiki, я решил описать ее более понятным способом + с комментариями при работе:
$arr = [4, 3, 2, 1];
$size = count($arr) - 1;
for ($i = 0; $i < $size; $i++) {
echo 'перебираем с 0 по ' . ($size - $i) . PHP_EOL;
for ($current = 0; $current < $size - $i; $current++) {// Здесь "-$i" это оптимизация, т.к. после завершения данного for, самое правое число является самым большим
$nextKey = $current + 1;
$nextValue = $arr[$nextKey];
if ($arr[$current] > $nextValue) {
echo 'в ' . implode(',', $arr) . ' число ' . $arr[$current] . ' > ' . $arr[$nextKey] . ' значит меняем их и получаем: ';
$arr[$nextKey] = $arr[$current];
$arr[$current] = $nextValue;
echo implode(',', $arr) . PHP_EOL;
}
}
}Источники: 1